
Tag: Сделал
новости и заметки по data engineering и data science, rss читалка, python, django, web parser, cron, docker
с помощью Python извлечь данные из базы данных MySQL Эгеи и положить в .csv или Google Sheets




В двух предыдущих заметках я рассказал, как собирал данные и приводил базовый анализ на самые-самые заметки

У агентства IT-Agency есть план обучения сотрудников — он открыт и опубликован на сайте



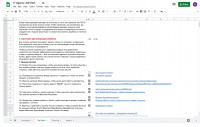
У агентства IT-Agency есть план обучения для сотрудников — он открыт и опубликован на их сайте

Если взять 90 лет по 52 недели и разложить их на одном листе — получится календарь жизни
Это вторая заметка из серии «Тренируем Python на блоге Ильи Бирмана»
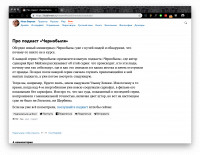
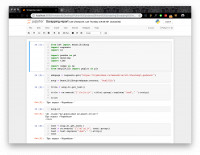
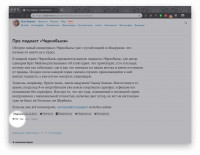
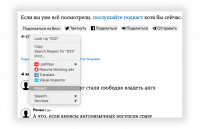
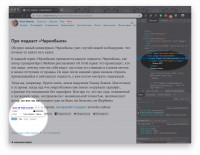
Веб-скрэпинг — это автоматизированный сбор данных с сайтов в интернете






На винде можно было тыкнуть в поле времени и появлялся календарь на месяц. На маке мне этого не хватает









Завершился второй модуль курса «Дизайн цифрового продукта» — показывали сделанные проекты



Провел его через несколько итераций с замечаниями «технического» и «арт-директора» — кураторов курса