
Как спарсить веб-страницу гугл-таблицей
У агентства IT-Agency есть план обучения для сотрудников — он открыт и опубликован на их сайте.
Я хочу пройти этот план, для этого решил сделать себе список материалов и ссылок, где я мог бы отмечать прогресс.
Три способа собрать данные в таблицу:
- Ручной. Можно скопировать всё руками: текст сюда, достать ссылку, поставить рядом, указать номер.
- Автоматический. Написать парсер на Питоне (как я делал с блогом Бирмана). Но потом придется всё равно как-то копировать данные в гугл-таблицы, где надо будет отмечать прогресс.
- Полуавтоматический. Как-то сразу получить данные с сайта в таблицы. Видел в гугл-таблицах формулы для импорта HTML.
Выбираю третий вариант — будут парсить сразу в гугл-таблицы.
Парсинг
Через внутреннюю справку ищу подходящую формулу для парсинга. Нахожу IMPORTHTML:
Imports data from a table or list within an HTML page.
Синтаксис формулы: IMPORTHTML(url, query, index). Здесь query это либо список, либо таблица. Удобно для узкой задачи, но у нас текст и заголовки — не подходит.
Смотрю похожие формулы, нахожу IMPORTXML:
Imports data from any of various structured data types including XML, HTML, CSV, TSV, and RSS and ATOM XML feeds.
Синтакс IMPORTXML(url, xpath_query), где
- url — ссылка,
- xpath_query — запрос на языке XPath.
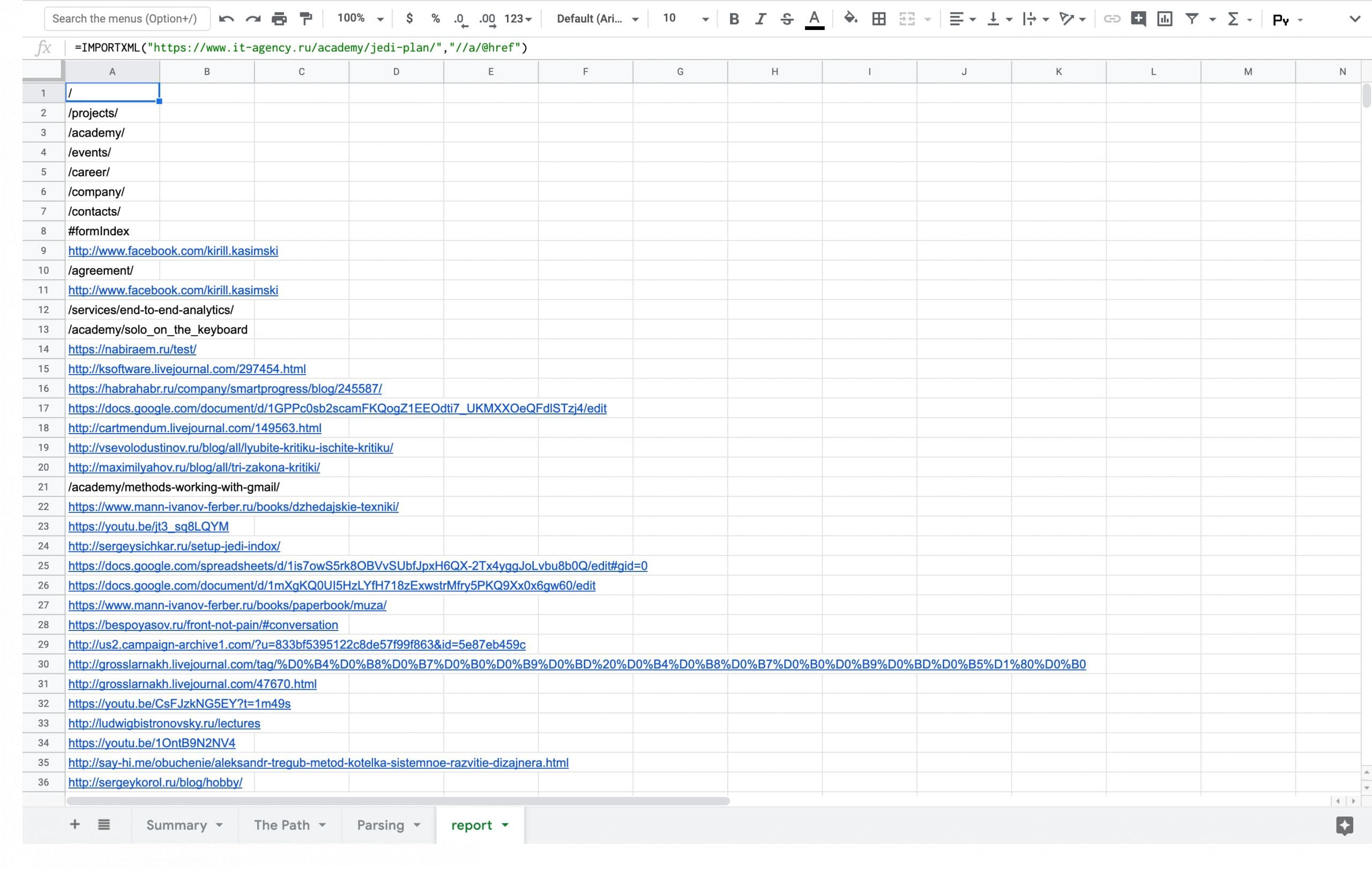
Вроде похоже. Для теста запускаю формулу с ссылкой на веб-страницу IT-Agency с параметром по умолчанию:
=IMPORTXML("https://www.it-agency.ru/academy/jedi-plan/","//a/@href")Получаю такой результат. Формула работает, остаётся отладить детали.
Иду на веб-страничку с планом и изучаю как выглядят нужные мне элементы через хром девтулс:
<h2 class="fix-after-p">I. Система организации работы</h2>
<p>1.1. <a href="/academy/solo_on_the_keyboard">Пройти Соло на клавиатуре</a>, чтобы экономить время, печатать быстро и без ошибок даже в темноте. Будет полезно, если <a href="https://nabiraem.ru/test/">в тесте</a> покажете скорость ниже 250 или допустите ошибок больше десяти.</p>Значит, мне нужны тэги h2, h3, p и атрибут href у тэгов a (адреса ссылок). Лезу в мануал изучать синтаксис языка XPath.
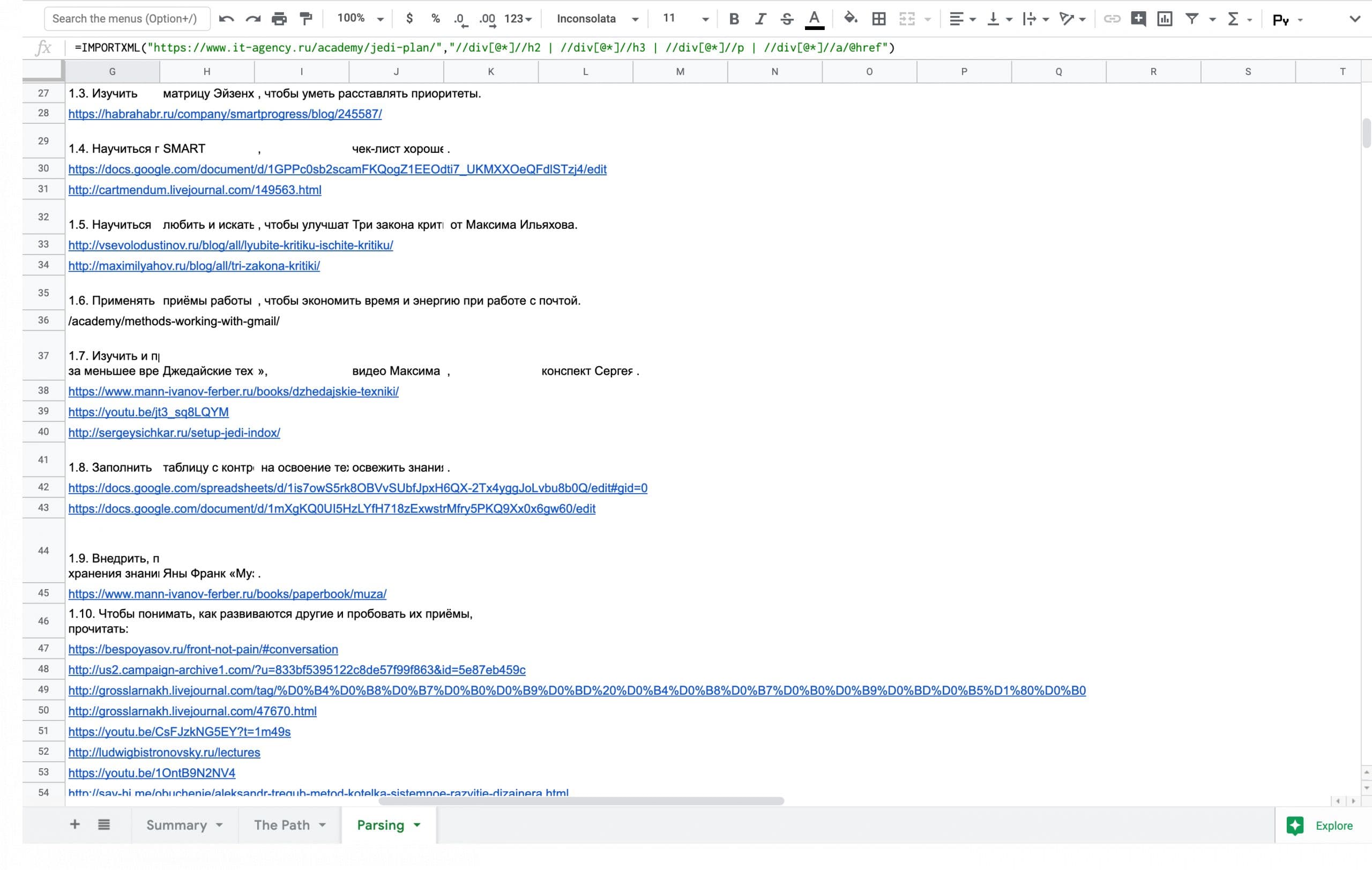
Чтобы убрать из выдачи технические элементы, добавил условие, что элементы должны быть дочерними от div с любым атрибутом. В результате получаю такую формулу:
=IMPORTXML("https://www.it-agency.ru/academy/jedi-plan/",
"//div[@*]//h2 | //div[@*]//h3 | //div[@*]//p | //div[@*]//a/@href")И весь текст с сайта, разбитый на колонки в таблице.
Обработка
С парсингом разобрался, теперь есть данные. Пока что выглядит не очень — здесь сложно отслеживать прогресс и изучать материалы. Оформим всё как надо.
Некоторые тэги p разбиты на несколько ячеек — соберём текст в одну ячейку через формулу JOIN.
Но список большой, хочу взять формулу и скопировать на всю длину. Но тогда она заджойнит и ссылки. Разделю на этом этапе текст и ссылки в разные колонки, чтобы потом получить удобный список.
Делаю ячейку True / False с детектором ссылок через простое регулярное выражение:
=REGEXMATCH(G20, "^((http.)|(/.))")Добавляю в формулу join проверку на условие True / False из ячейки с детектором ссылки:
=if(NOT(C20), join(" ", G20:AL20), "")В соседнюю колонку собираю отдельно ссылки по тому же условию только инвертированному
=if(NOT(C23), "", G23)Получаю две колонки: отдельно весь текст и все ссылки
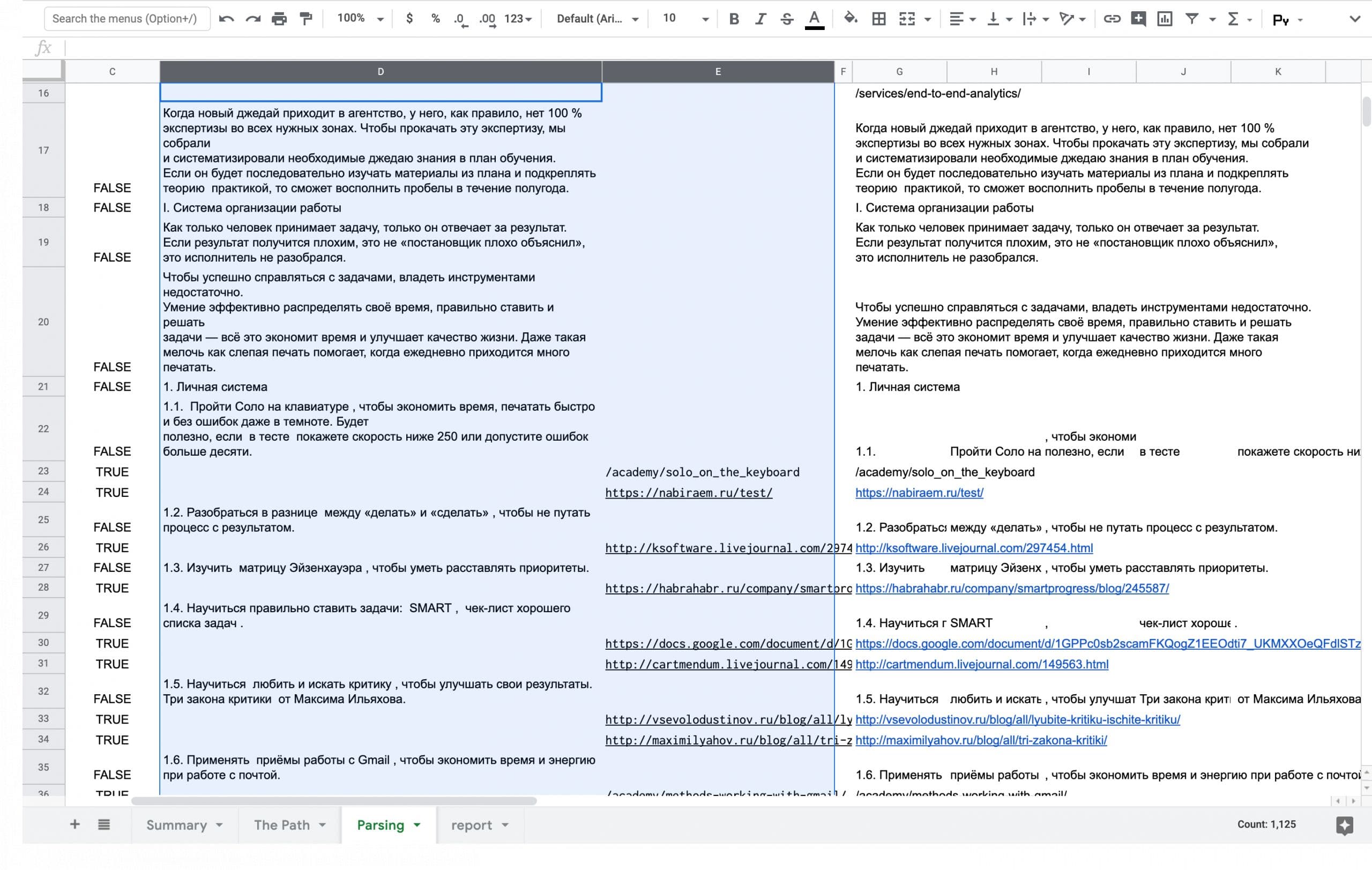
Эти две колонки удобно взять и скопировать на новый лист, чтобы оформить.
Оформление
Копирую колонки с текстом и ссылками на новый лист. Использую копирование, а не автоматические ссылки, чтобы зафиксировать ячейки. Дальше будет оформление и не хочу, чтобы оно потом «поползло». На этом этапе теряется автоматизация — если страница на сайте агентства поменяется, то контент в таблице останется прежним.
Заменил дефолтный шрифт Arial на приятный Proxima Nova, который чем-то похож на шрифт Gerbera на сайте агентства.
Взять фирменный цвет агентства с их сайта — #D82C2C
Добавим условное форматирование цвета заголовков через регекс:
=regexmatch(B1,"^[I, V, X]")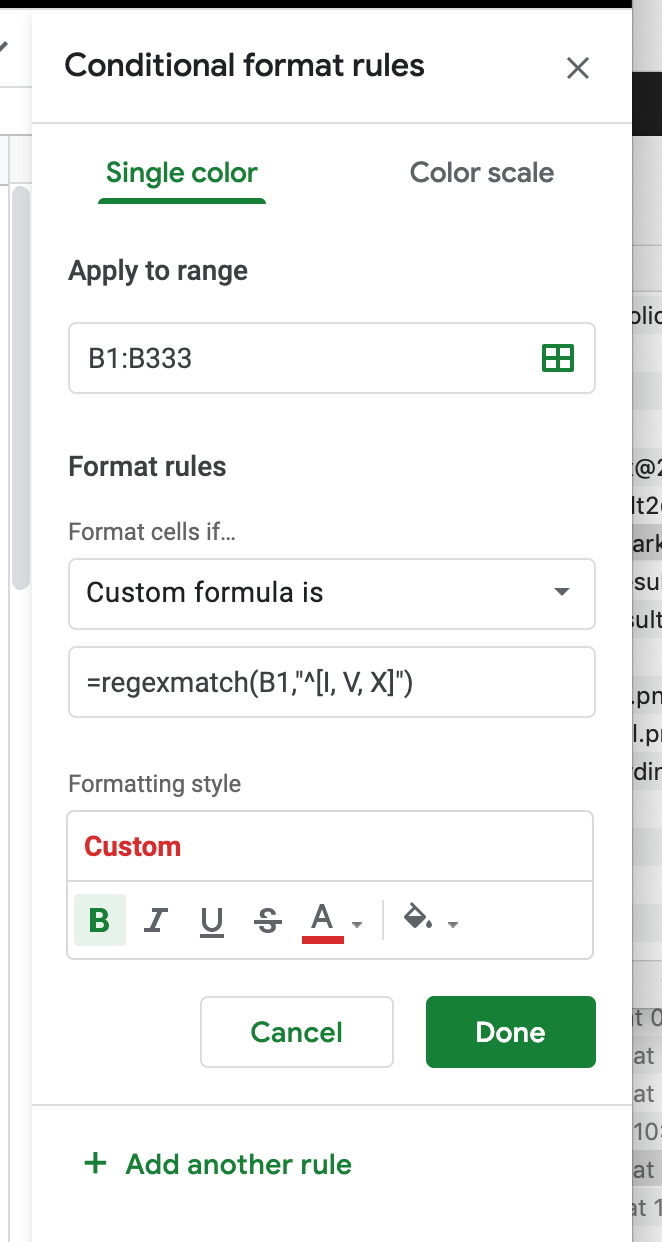
Оформить заголовок, добавить туда ссылку на оригинал.
Через ручной поиск и замену исправить внутренние ссылки типа /academy/… до полных www.it-agency.ru/academy/…
Сделаем ссылки great again — добавим каждой название. Для этого спарсим название страницы по каждоый ссылке:
=join(" — ",IMPORTXML(J14, "//h1"))Так, например из ссылки http://vsevolodustinov.ru/blog/all/lyubite-kritiku-ischite-kritiku/ получим «Блог Всеволода Устинова — Любите критику, ищите критику»
Из ссылки и спарсенного названия составляем красивую ссылку через формулу HYPERLINK
=hyperlink(J9,IF(iserror(K9), J9,K9))Получаем название со ссылкой Блог Всеволода Устинова — Любите критику, ищите критику
В таблицах есть какое-то системное ограничение на парсинг, поэтому только часть из 290 формул смогли спарсить название страницы. Для этого в формулу HYPERLINK добавил проверку на ошибку парсинга — если есть ошибка, то название ссылки будет самой ссылкой.
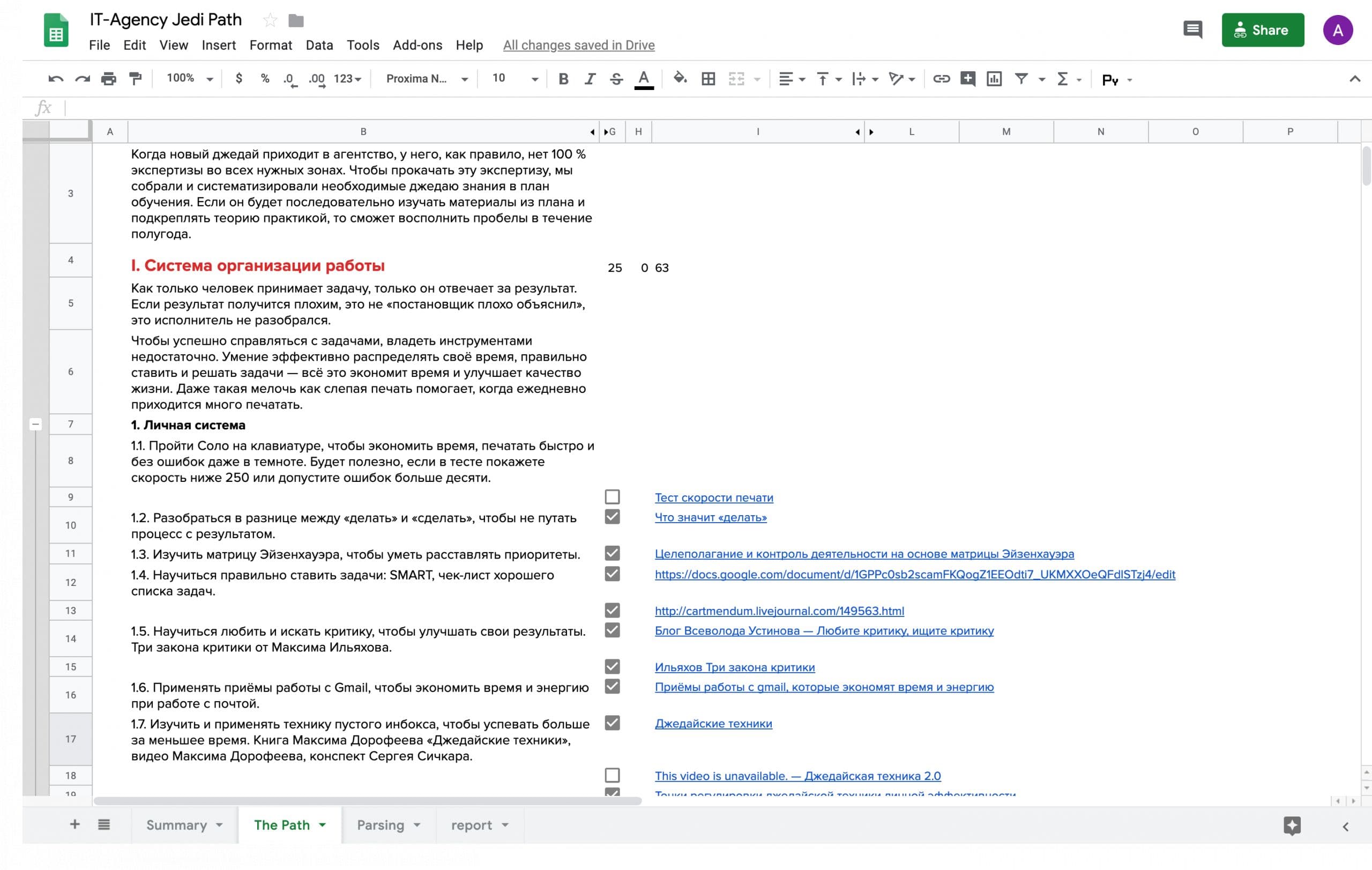
У каждой ссылки ставим чекбокс, чтобы не забыть, что уже прочитал. Чтобы разделить ссылки на открытые и внутренние, я ставил чекбоксы в два разных столбца для каждого типа.
Группируем строки по темам, чтобы было легче перемещаться по всей длине документа.
Скрываем рабочие поля, получаем опрятную страницу.
Дешборд с прогрессом
Теперь eсть список материалов по теме с чекбоксами у каждой ссылки. Хочу видеть общую информацию о прогрессе по каждой области на отдельной странице. Такие страницы со сводкой называют дешбордами (dashboard).
Чтобы понять прогресс по каждому разделу, нужно знать, сколько чекбоксов отмечено — считаем по формуле:
=COUNTIF(G9:G73, True)Рядом так же считаем столбец с чекбоксами внутренних ссылок. И считаем общее количество ссылок в разделе.
Здесь на каждый раздел пришлось руками ставить границы формулы. Не придумал, как можно автоматизировать.
Делаю новый лист. С помощью SQL-подобного запроса соберём с листа названиями разделов. Повезло, что они пронумерованы римскими цифрами — это упрощает дело. Есть всего три знака, с которых может начинаться искомые строки: ’I’, ’V’ или ’X’.
=QUERY('The Path'!B:B,
"select B WHERE B IS NOT NULL
AND (B LIKE 'I%' OR B LIKE 'V%' OR B LIKE 'X%')")Через VLOOKUP собираем счётчики по каждому разделу
=VLOOKUP($B6,'The Path'!$B:$I,6,FALSE)Получается 4 числа:
- сколько пройдено открытых материалов,
- сколько пройдено закрытых,
- сколько всего материалов,
- и ещё сколько из них открытых.
Чтобы понимать прогресс из этих цифр собираем строку вида «25 / 63» формулой
=sum(F6:G6)&" / "&H6Рядом тот же прогресс в процентах.
Подбиваем «Итого» — в числах и в процентах.
Выводим прогресс в заголовок: собираем строку из имени и процента.
=A1&" — джедай на "&ROUND(E19*100)&" %"Получается такой дешборд-сертификат-грамота
