
Тренируем Python: веб-скрэпинг на примере блога Ильи Бирмана
Веб-скрэпинг — это автоматизированный сбор данных с сайтов в интернете.
Часто применяется, например, интернет-магазинами, чтобы следить за ценами и ассортиментом конкурентов. Ещё можно получить с сайта NASA данные об орбитах всех космических тел в Солнечной системе.
Это первая заметка из серии «Тренируем Python на блоге Ильи Бирмана».
- Сбор данных
- Анализ данных
- Визуализация результатов
Зачем всё это
На майских праздниках я начал изучать язык программирования Python.
Пайтон привлёк меня своей универсальностью: можно быстро что-нибудь автоматизировать, написать скрипт для веб-скрэпинга или проанализировать пару миллионов записей в базе данных. А если прокачаться в математическом анализе, теории вероятностей и линейной алгебре, можно писать код для машинного обучения.
На платформе Code Academy я изучил основы языка, прошёл несколько курсов, сделал много учебных примеров. По итогам решил сделать выпускной проект (бывает выпускной через месяц?), чтобы потренироваться на живом примере и на практике освоить полученные знания.
В теории нет разницы между теорией и практикой. А на практике есть
Йоги Берра — американский бейсболист и менеджер бейсбольной команды.
Выбор объекта исследования
Для объекта исследования выбрал блог Ильи Бирмана — дизайнера и арт-директора, диджея и музыканта, преподавателя и писателя, философа и математика, фотографа и путешественника, автора блога и видео-заметок.
3 причины такого выбора:
- Илья — интересный человек. Это, кажется, главное в личных проектах — чтобы было интересно и безудержно пёрло от процесса;
- большой массив данных для изучения: Илья регулярно ведёт блог с 2003 года;
- в блоге есть отдельная страничка со всеми-всеми записями — идеально для первого скрэпинга (ведь я ещё не знаю, как автоматически листать страницы);
- БОНУС! — передать привет Илье и сгенерировать ему просмотров на сайт (два или, может, даже три).
Инструменты
- Python. Плюс дополнительные библиотеки:
- BeautifulSoup + Requests — для, собственно, веб-скрэпинга
- RE — для очистки данных с помощью регулярных выражений
- Pandas — для хранения и обработки полученных данных
- Matplotlib и Seaborn — для визуализации результатов
- Jupyter Notebook — визуальная среда для кодинга
- Chrome DevTools — чтобы понять как устроен искомый сайт внутри
- Google и StackOverflow — чтобы понять, мой идеальный код не работает.
Знакомство с объектом исследования
Итак, есть блог Ильи Бирмана — https://ilyabirman.ru/meanwhile/
Блог работает на движке Эгея — кстати, тоже проект Ильи. У Эгеи есть отдельная страница со всеми записями. Для блога Ильи она доступна по адресу https://ilyabirman.ru/meanwhile/all/

Страница отдельной заметки:
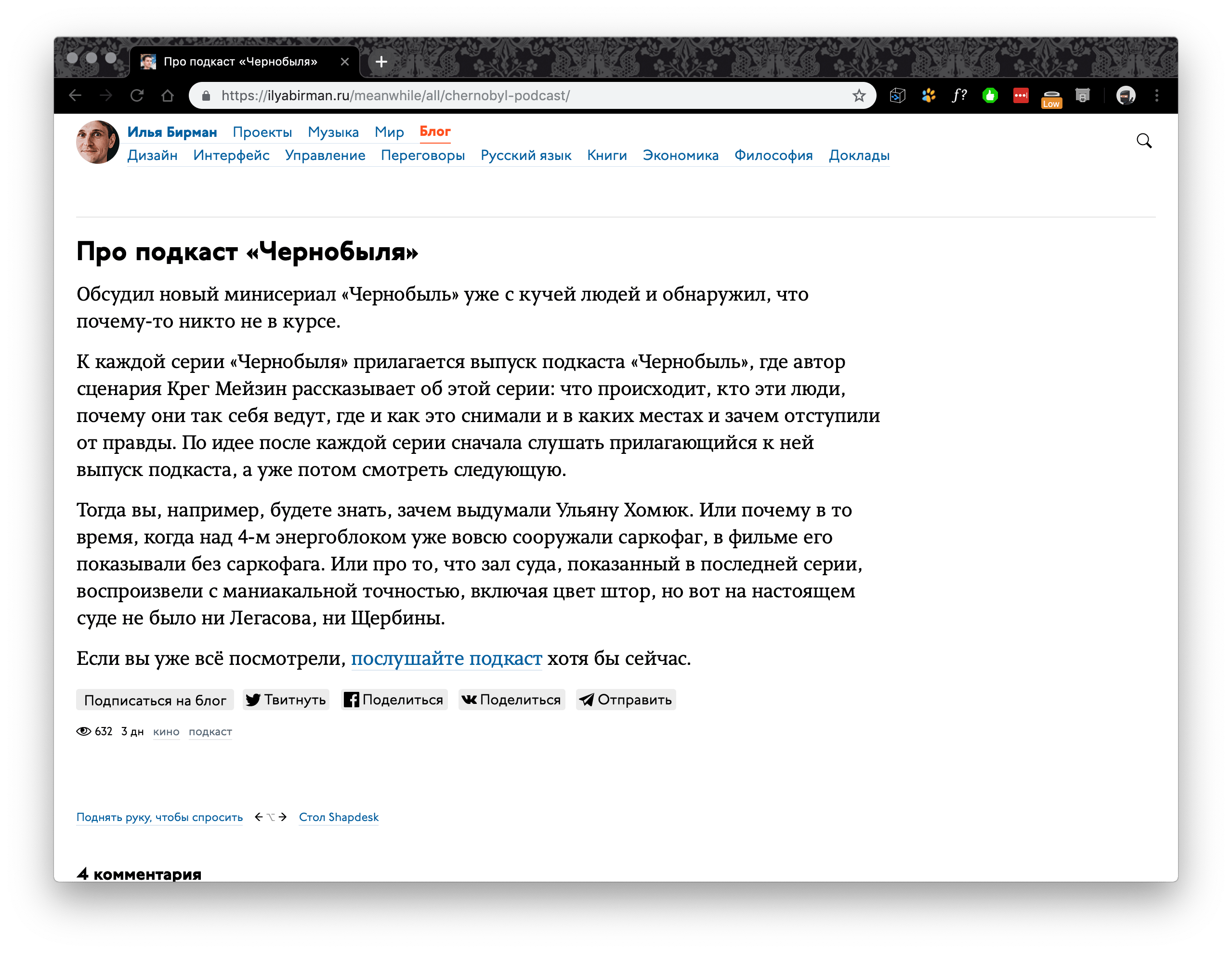
Какие параметры для исследования здесь можно добыть:
- заголовок заметки, куда без него;
- количество просмотров — можно найти самые просматриваемые;
- количество комментариев — найти самые обсуждаемые заметки;
- тэги заметки — может пригодиться;
- дату публикации — чтобы привязать данные ко времени;
- количество картинок — для общей картины;
- количество слов в заметке — интересно будет поискать корреляцию длины с просмотрами или комментариями;
- URL — чтобы потом включить в отчёт и быстро находить нужные заметки.
К делу — расчехляем Python
Писать код удобно в Jupyter Notebook. Это визуальная среда для программирования, где можно сразу посмотреть результат.

Импортируем нужные библиотеки
from bs4 import BeautifulSoup
import requests
import reЧтобы разобраться, как добывать данные из веб-страницы, начнём с простого: возьмём одну заметку и попробуем добыть информацию из неё.
С помощью requests обращаемся к странице блога со всеми записями. И с помощью BeautifulSoup делаем «мыло» — soup объект.
webpage = requests.get("[https://ilyabirman.ru/meanwhile/all/chernobyl-podcast/](https://ilyabirman.ru/meanwhile/all/)")
soup = BeautifulSoup(webpage.content, "html.parser")Заголовок заметки
С объектом soup уже можно работать: например, достать оттуда заголовок — тэг h1:
soup.h1На это но выдаст весь тэг h1:
<h1 class="e2-published e2-smart-title">Про подкаст «Чернобыля»</h1>Достать только видимую часть — текст — можно через метод .get_text():
title = soup.h1.get_text()На выходе получили «\r\nПро\xa0подкаст «Чернобыля» \r\n». Похоже на правду, но не совсем.
\xa0, \r и \n — это специальные символы. На сайте браузер их не показывает, но после конвертации в строку они «проявились». Почистим данные с помощью регулярных выражений — библиотека re.
title = re.search("[^(\n|\r)]+", title).group()На выходе строка: ‘Про\xa0подкаст «Чернобыля» ’
Функция search библиотеки re возвращает объект match. Чтобы получить на выходе обычную строку, надо добавить метод .group()
На все попытки засунуть в регулярное выражение ещё и \xa0, Пайтон упорно выдавал ошибку. Не понял как сделать поиск всё в одном, пришлось пройтись по тексту ещё раз простой заменой через .replace().
Меняем неразрывный пробел на обычный. Заодно удаляем пробелы в начале и конце.
title = title.replace("\xa0"," ").strip()На выходе нужная строка: ‘Про подкаст «Чернобыля»’
Просмотры
С заголовком заметки было просто — элемент h1 обычно только один на странице. Мы обратились к нему по типу, без дополнительного поиска.
С более простыми элементами сложнее: обычно их больше одного на странице. Чтобы с помощью BeautifulSoup найти нужный элемент, нужно о нём что-нибудь знать.
Здесь поможет встроенный инструмент браузера Chrome — DevTools — с его помощью можно залезть сайту под капот и посмотреть как там всё устроено.
Ищем на странице заметки счётчик просмотров:

Смотрим, как он выглядит в html коде. В Хроме наводим на элемент и нажимаем inspect

Или можно горячими клавишами shift+command+c открыть DevTools и навести на нужный элемент.
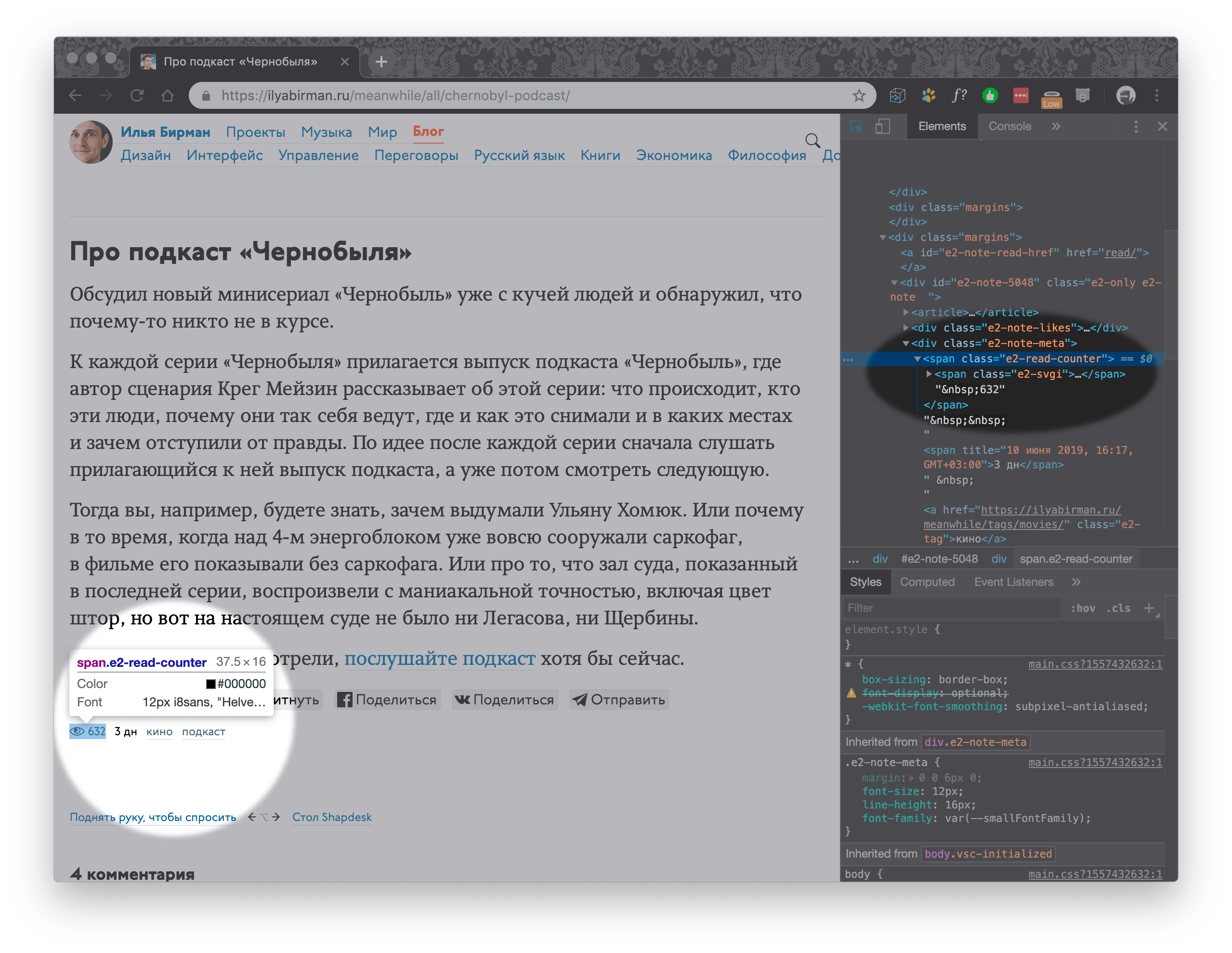
Искомая цифра 632 находится внутри тэга с классом e2-read-counter :
<div class="e2-note-meta">
<span class="e2-read-counter">
<span class="e2-svgi"> … </span>
632</span>
<…>
</div>С помощью BeautifulSoup обращаемся к элементу по его классу:
views_span = soup.select(".e2-read-counter")[0].get_text()На выходе получаем « 632 ». ПРЯМОЕ ПОПАДАНИЕ! — не перестаю удивляться мощи программирования.
Выглядит как цифры но на самом деле это текст (да ещё и с пробелом!). Тип переменной проверяется через функцию type():
>>> print(type(views_span))
<class 'str'>Через уже знакомые регулярные выражения добудем из этого текста только цифры:
views_span = re.search("\d+", views_span).group()И переведём текст в цифры — тип integer:
views_span = int(views_span)>>> print(type(views_span))
<class 'int'>Итого: у нас уже есть заголовок заметки и количество просмотров.
Обработка исключений
Забегая вперёд, расскажу об обработке исключений. Написанный код отлично работает на одной свежей заметке из блога. Как показала практика, это вовсе не означает, что он будет работать на всех 4486 страницах.
На заметках старше 2017 года код начал выдавать ошибку. Я добавил отладчик в код, чтобы он показывал адрес страниц, где была ошибка. Заходил туда и пытался понять, в чём проблема. На вид эти страницы ничем не отличались от других. Кроме того что просмотров у них было 1.
Видимо, Эгея не сразу умела отображать просмотры страницы, но в какой-то момент научилась. На страницах, опубликованных до этого момента, просто нет тэга с классом e2-read-counter. Зато при первом заходе на такую страницу через браузер (но не через парсер!) Эгея его автоматически добавляет прямо налету.
Не знаю, как матёрые питонисты обрабатывают исключения, мне пришло в голову проверять наличие нужного элемента через его длину:
if len(soup.select(".e2-read-counter")) > 0:
…сбор данных…
else:
views = 0Если такого элемента на странице нет, то считаем, что просмотров ноль.
Комментарии
По примеру счётчика просмотров повторяем всю процедуру. Ищем элемента на странице. Видим, что комментарии в коде идут так:
<span id="e2-comments-count">4 комментария</span>Здесь у тэга указан айди, а не класс (как у тэга с просмотрами). Пришлось воспользоваться другим методом BeautifulSoup — .find()
Комментарии — это тебе не просмотры. Здесь даже мне было очевидно, что у заметки их может и не быть, поэтому обработчик я добавил сразу.
if soup.find(id="e2-comments-count") != None:
comments_span = blog_page_soup.find(id="e2-comments-count").get_text()
comments = (int(re.search("\d+", comments_span).group(0)))
else:
comments = 0Всё по аналогии с просмотрами: ищем элемент, забираем текст, выуживаем число, переводим в интеджер.
Если элемента с комментариями нет, значит, их ноль.
Тэги
Повторяем знакомую процедуру для тэгов заметки.
<div class="e2-note-meta">
…
<a href="https://ilyabirman.ru/meanwhile/tags/movies/" class="e2-tag">кино</a>
<a href="https://ilyabirman.ru/meanwhile/tags/podcast/" class="e2-tag">подкаст</a>
</div>Новый челендж: в отличие от счётчиков, тэгов может быть несколько. Удобно, что к них есть отдельный класс, по которому можно обратиться. Делаем цикл по всем элементам с нужным классом и добавляем все элементы в заготовленный список:
tags = []
for tag in soup.select(".e2-tag"):
tags.append(tag.get_text())Проверяем, что получается:
>>> print(tags)
['кино', 'подкаст']Всё норм!
Картинки
Подумал, что хорошо бы ещё знать, сколько было в заметке картинок. Не самая важная метрика, но было интересно попрактиковаться.
В нашей подопытной заметке про подкаст картинок нет, поэтому берём заметку про Черногорию. Смотрим в DevTools на первую картинку. HTML выглядит так:
<div class="e2-text-picture-imgwrapper" style="padding-bottom: 66.67%">
<img src="https://ilyabirman.ru/meanwhile/pictures/kotor-DSCF1378.jpg" width="1200" height="800" alt="">
</div>Решил получить нужную цифру через див: находим на странице все дивы с нужным классом: soup.find_all(“div”, class_=“e2-text-picture-imgwrapper”). Метод .find_all() возвращает список найденных элементов. То есть количество нужных элементов на странице — это длина этого списка.
images = len(soup.find_all("div", class_="e2-text-picture-imgwrapper"))Проверяем:
>>> print(images)
16На всякий случай пойдём и посчитаем пальчиком все фотографии Черногории в заметке — получилось 16. Работает.
Длина текста
Для полноты данных соберём длину текста заметки. Через DevTools ищем элемент, который содержит в себе только заметку, без прочего «обвеса». Находим элемент article. Отдельный и единственный — удобно будет к нему обращаться.
Подумал, что длину хорошо быть мерять в словах, а не символах, — будет нагляднее.
Чтобы получить длину в словах, достанем текст элемента article и разделим его на слова методом .split(). В качестве параметра функция принимает любой разделитель. Если параметр не указан — считает разделителем пробельные символы.
Функция .split() возвращает список слов. Количество слов — длина этого списка. Сохраняем в переменную.
words = len(soup.article.get_text().split())Дата публикации
Оставил самое сложное на десерт. С датой возился дольше всего, в итоге получился большой кусок кода.
Начнём стандартно: через DevTools ищем в коде страницы дату. Находим такое:
<div class="e2-note-meta">
<span class="e2-read-counter">
<span class="e2-svgi">
<svg…> … </svg>
</span>
624
</span>
<span title="10 июня 2019, 16:17, GMT+03:00">3 дн</span>
<a…> … </a>
</div>То есть дата публикации спрятана в title элемента span без какого-либо класса внутри элемента div с классом e2-note-meta. Все предыдущие данные мы доставали, обращаясь к элементу через его уникальный class или id. С датой такой подход не прокатит — у элемента нет ни того, ни другого. Зато у него есть title, он и он у каждой заметки свой.
Решил добраться до нужного элемента через его родителя — элемент див с уникальным классом. И обратиться напрямую к его четвертому дочернему элементу:
>>> soup.find("div", class_="e2-note-meta").contents[3]
<span title="10 июня 2019, 16:17, GMT+03:00">3 дн</span>Код сработал!
Но, как и в случае с просмотрами, меня ждал сюрприз, когда выкатил этот код на весь объём блога. Оказывается-то, блок с просмотрами тоже дочерний элемент дива, через который я обращаюсь к элементу с датой. И, когда у заметки нет просмотров, порядок дочерних элементов меняется, и span с датой уже не четвёртый (и даже не третий — это я сразу проверил!).
Решение пришло на прогулке, куда я вышел после долгих попыток подгадать новый порядковый номер нужного элемента и чтобы он подходил для всех заметок. Оказалось, что в номере просто нет смысла, можно же вложить поиск внутри поиска и найти `span` с датой по другому его уникальному свойству, которое однозначно отличает его от соседей — полному отсутствию класса.
>>> date = soup.find("div", class_="e2-note-meta").find("span", class_="")
<span title="10 июня 2019, 16:17, GMT+03:00">3 дн</span>Е-е-е-е!
Дело за малым — вытащить оттуда дату. Так, применяем уже стандартный подход с .get_text():
>>> date.get_text()
3 днОтлично, блин! — получили возраст публикации. Сама дата-то не внутри элемента, а в его title. Начинаем ~~изобретать велосипед~~ применим регулярные выражения.
>>> date_str = re.search("\".+\"", str(date)).group(0)
"10 июня 2019, 16:17, GMT+03:00"Уже лучше. Пока ещё просто строка с датой и кавычками, но уже не возраст.
Из этой строки нужно достать: день, месяц, год. Повезло, что каждый из этих данных можно уникально закодировать через регулярные выражения:
- день — единственные одна или две цифры в строке;
- месяц — буквы между двумя пробелами;
- год — единственные четыре цифры в строке.
Для дня и года всё бесхитростно, переводим на язык регулярных выражений:
day = int(re.search("[\d]{1,2}", date_str).group(0))
year = int(re.search("[\d]{4}", date_str).group(0))С месяцем надо повозиться. Поскольку длина всех месяцев разная (в отличие от дней и годов), то поиск задаём как “буквы без цифр между двумя пробелами”.
В регулярных выражениях буквы можно задавать через последовательности, например, поиск по [a-zA-Z] выдаст все буквы в нижнем и верхнем регистре.
Ещё есть сокращения типа \w, что даст такой же результат как и [a-zA-Z0-9_].
Больше такого в английской документации к библиотеке re или на русской википедии
Воспользуемся вторым примером, но уберём оттуда цифры. И сразу уберём пробелы, по которым искали буквы.
>>> month_str = re.search(" [\w^(\d)]+ ", date_str).group(0).strip()
июняГут, идём дальше.
Чтобы потом было легче работать с датами, хорошо бы иметь дату в цифровом виде. Значит, надо перевести месяц в число. Наверняка, есть какие-то элегантные способы, но я поступил топорно: вбил руками список всех месяцев в родительном падеже и искал порядковый номер строки в этом списке:
months = ["января", "февраля", "марта", "апреля", "мая", "июня",
"июля", "августа", "сентября", "октября", "ноября", "декабря"]
month_int = months.index(month_str) + 1Помните, что индексы идут с нулевого?
Для полной картины ещё соберём часы и минуты публикации. Вдруг захотим построить график средней суточной активности по годам.
time_ = re.search("[\d]{2}:[\d]{2}", date_str).group(0)
hour = int(time_[0:2])
minute = int(time_[3:5])Для работы со временем и датой в Пайтоне есть специальный объект —datetime. Удобнее всего хранить дату в нём.
date_time = datetime.datetime(year, month_int, day, hour=hour, minute=minute)Итак, мы собрали все необходимые данные на примере одной заметки:
- заголовок;
- количество просмотров;
- количество комментариев;
- тэги заметки;
- количество картинок;
- количество слов в заметке;
- дата публикации.
Ещё не хватает URL заметки, добавим позднее.
Теперь надо собрать такие же данные со всех 4486 заметок.
Массовый скрэпинг
Собираем цикл, который пойдёт по по всем заметкам и будет собирать данные по каждой. Скармливаем коду нужную страницу и делаем из неё «мыло».
webpage = requests.get("https://ilyabirman.ru/meanwhile/all/")
soup = BeautifulSoup(webpage.content, "html.parser")Подготовим пустые списки для каждого типа данных, куда будем собирать результаты.
titles = []
views = []
comments = []
tags = []
datetimes = []
images = []
words = []
links = []Запускаем цикл для обработки всех ссылок на странице. На языке HTML ссылки обозначаются тэгами a.
for link in soup.find_all("a"):
…Проход цикла по всем 4486 заметкам занимает продолжительное время, поэтому сначала лучше ограничить цикл, чтобы отладить код. Я начал с ограничения в 50 записей и по мере улучшения выкатывал на 100-400-1000-2000 записей.
Ограничитель на первые 50 элементов — стандартный синтаксис для работы со списками:
for link in soup.find_all("a")[:50]:
…Оказалось, что не все тэги a содержат какие-то ссылки. Добавил в начале соответствующий обработчик: if type(link.get(‘href’)) == type(“string”)
Ещё оказалось, что на странице куча ссылок не на заметки, а на рабочие моменты блога, типа настроек и списка тегов. Пришлось вручную проверять ссылки на наличие в них строк @ajax, /settings/ и /tags/.
Контрольный выстрел: пропускать все ссылки короче 32 знаков (длина строки «https://ilyabirman.ru/meanwhile/», с которой начинаются ссылки всех заметок).
Сначала я отбирал ссылки по наличию в них http://ilyabirman.ru/meanwhile/all/ — адреса всех свежих заметок начинались так. Это дало чистые результаты. Но, когда выкатил цикл на все 4486 заметок, он дал результаты только в две тысячи. Адреса более ранних заметок больше не содержали «/all/». Пришлось внести коррективы.
После обработки всех исключений, цикл доходит до ссылки на очередную заметку. Чтобы её обработать, нужно и из неё сделать объект soup:
for link in soup.find_all("a"):
post_tags = []
parse_count += 1
# drop not links (there are some 'None' object in scrapping results)
if type(link.get('href')) == type("string"):
# exclude blog engine settings links
if ("@ajax" in link.get('href'))\
| ("/settings/" in link.get('href'))\
| ("/tags/" in link.get('href'))\
| (len(link.get("href")) <= 32) : # 32 is the length of "<https://ilyabirman.ru/meanwhile/>"
continue
# drop all except links for blogposts
elif "ilyabirman.ru/meanwhile/" in link.get('href'):
# get a link itself and parse it with with BeautifulSoup
blog_page = requests.get(link.get('href'))
blog_page_soup = BeautifulSoup(blog_page.content, "html.parser")Логика немудрёная: иди на страницу со всеми записями и найди там все ссылки, каждую ссылку проверь по условиям, если всё ок — делай из страницы по этой ссылке объект soup.
В итоге наш цикл оказывается на страничке очередной заметки. На этой странице надо собрать все данные с помощью кода, который мы разбирали в начале. Чтобы не повторяться, привожу конечный результат. Разбор есть выше, да и в коде оставил построчные комментарии.
для экономии места уберу отступ; приведённый код внутри цикла, описанного выше;
# get a blogpost title, save to list of titles
titles.append(blog_page_soup.h1.get_text())
# check if a post have a view counter (old posts have no views counter)
if len(blog_page_soup.select(".e2-read-counter")) > 0:
# get a span block with views count
views_span = blog_page_soup.select(".e2-read-counter")[0].get_text()
# get a number from text block and format as integer, save to list of views count
views.append(int(re.search("\d+", views_span).group(0)))
else:
views.append(1)
# get comments count
if blog_page_soup.find(id="e2-comments-count") != None:
comments_span = blog_page_soup.find(id="e2-comments-count").get_text()
comments.append(int(re.search("\d+", comments_span).group(0)))
else:
comments.append(0)
# get tags for each post
for tag in blog_page_soup.select(".e2-tag"):
post_tags.append(tag.get_text())
# list of posts' tags
tags.append(post_tags)
# append date and time for each post to the list
append_datetime_from_soup(blog_page_soup, datetimes)
# get images count
images.append(\
len(blog_page_soup.find_all("div", class_="e2-text-picture-imgwrapper")))
# post's length (words count)
words.append(len(blog_page_soup.article.get_text().split()))
# get link
links.append(link.get('href'))Кусок кода с добычей даты из строки получился больше остальных, поэтому вывел его в отдельную функцию. Подозреваю, что хорошей практикой было бы написать такие функции для каждого параметра.
def append_datetime_from_soup(source_soup, list_with_results):
span_datetime = str(source_soup.find("div", class_="e2-note-meta")\
.find("span", class_=""))
# get string with date and time from <span> title
date_str = re.search("\".+\"", span_datetime).group(0)
# get day: one or two digits
day = int(re.search("[\d]{1,2}", date_str).group(0))
# get month as string
month_str = str(re.search(" [\w^(\d)]+ ", date_str).group(0))
month_str = month_str.strip()
# convert string to integer
months = ["января", "февраля", "марта", "апреля", "мая", "июня",
"июля", "августа", "сентября", "октября", "ноября", "декабря"]
month_int = months.index(month_str) + 1
# get year
year = int(re.search("[\d]{4}", date_str).group(0))
# get time
time_ = re.search("[\d]{2}:[\d]{2}", date_str).group(0)
hour = int(time_[0:2])
minute = int(time_[3:5])
# make a datetime object
date_time = datetime.datetime(year, month_int, day, hour=hour, minute=minute)
# append to the result
list_with_results.append(date_time)После того как получили результаты — проверьте их правильность. Сколько циклов прошёл парсер? Сколько результатов на выходе? Длина всех списков с результатами одинаковая?
Проверяем результаты:
>>> print(parse_count, len(views), len(images), len(words))
4536 4489 4489 4489Итого 4536 проходов сделал парсер и собрал списки данных длиной 4489 записей каждая.
Списки с данными одной длины — это хорошо. Но записей больше, чем заметок, но не намного. Видимо, есть лишние или дубликаты. Разберёмся с ними на следующем этапе.
Что дальше?
Чтобы проанализировать собранные данные, воспользуемся библиотекой pandas и запихнём наши списки в одну большую таблицу на стероидах — dataframe.
dict = {"title": titles,
"datetime": datetimes,
"views": views,
"comments": comments,
"length": words,
"images": images,
"tags": tags_as_string,
"link": links}
birman_frame = pd.DataFrame(data = dict)В итоге получаем удобную для анализа структуру. Можно, например, посмотреть заметки с наибольшим количеством просмотров за всё время.

На этом первая часть отчета закончена. В следующих сериях — анализ собранных данных и визуализация полученных выводов.