
Tag: Накодил




В двух предыдущих заметках я рассказал, как собирал данные и приводил базовый анализ на самые-самые заметки
Это вторая заметка из серии «Тренируем Python на блоге Ильи Бирмана»
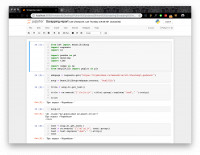
Веб-скрэпинг — это автоматизированный сбор данных с сайтов в интернете